https://huggingface.co/learn/llm-course/chapter1/1
Introduction - Hugging Face LLM Course
2. Using 🤗 Transformers 3. Fine-tuning a pretrained model 4. Sharing models and tokenizers 5. The 🤗 Datasets library 6. The 🤗 Tokenizers library 9. Building and sharing demos 10. Curate high-quality datasets 11. Fine-tune Large Language Models 12.
huggingface.co
챕터 1~4: Transformers 라이브러리의 메인 컨셉에 대한 소개.
- Transformer 모델의 작동 원리
- Hugging Face Hub 모델의 사용 방법
- 데이터셋을 활용한 파인튜닝 방법
챕터 5~8: Datasets, Tokenizers 라이브러리 기초.
- 가장 많이 사용되는 언어 처리 챌린지를 직접 실습
챕터 9: Hub에 모델 데모 공유.
챕터 10~12: 고급 LLM 토픽.
- 파인튜닝
- 고퀄리티 데이터셋 큐레이팅
- 추론 모델 빌드
1.1 Introduction
Hugging Face 생태계의 라이브러리(Transformers, Datasets, Tokenizers, Accelerate)와 Hugging Face Hub를 사용해 LLM과 NLP에 대해 배워보는 코스이다.
Google Colab Setup
Colab에서 실습할 수 있도록 환경을 구축해 두자.
파이썬 패키지 매니저인 `pip`를 사용해 Transformers 라이브러리를 설치한다.
(노트북에서는 `!` 문자로 시작함으로써 시스템 명령어를 사용할 수 있다.)
!pip install transformers
파이썬 런타임 내에 import해서 패키지가 잘 설치되었는지 확인 가능하다.
import transformers
위 명령어로 설치할 수 있는 것은 아주 가벼운 버전의 Transformers이다.
실습에서는 라이브러리의 아주 많은 feature를 사용할 예정이므로, 거의 모든 케이스의 의존성을 만족하는 development 버전을 설치하는 것을 추천한다고 한다.
아래 명령어로 설치하면 된다. 조금 오래 걸린다.
!pip install transformers[sentencepiece]
NLP와 LLM 이해하기
차이점
- NLP(Natural Language Processing)이란, 컴퓨터가 인간의 언어를 이해/해석/생성할 수 있도록 하는 데 중점을 둔 더 광범위한 분야이다. 감정 분석, 개체명 인식, 기계 번역 등 다양한 기술과 작업을 포함한다.
- LLM(Large Language Models)은 NLP 모델의 강력한 부분집합이다. 방대한 크기, 광범위한 학습 데이터, 최소한의 작업별 학습으로 광범위한 언어 작업을 수행할 수 있는 능력이 특징이다. 예시로는 Llama, GPT, Claude 시리즈 같은 모델이 있다.
1.2 자연어 처리와 대규모 언어 모델
자연어 처리(NLP)란?
NLP는 인간 언어와 관련된 모든 것을 이해하는 데 중점을 둔 언어학 및 머신러닝 분야이다.
NLP 작업의 목표는 단어 하나를 개별적으로 이해하는 것뿐만 아니라 해당 단어의 맥락을 이해하는 것이다. 다음은 일반적인 NLP 작업 목록과 그 예시이다.
- 전체 문장 분류: 리뷰의 감정 파악, 스팸 이메일 감지, 문장이 문법적으로 올바른지 혹은 두 문장이 논리적으로 관련되어 있는지 확인
- 문장의 각 단어 분류: 문장의 문법적 구성요소(명사, 동사, 형용사) 또는 명명된 개체(사람, 위치, 조직) 식별
- 텍스트 내용 생성: 자동 생성된 텍스트로 프롬프트 완성, 마스킹된 단어가 있는 텍스트의 빈칸 채우기
- 텍스트에서 답변 추출: 질문과 맥락이 주어지면 맥락에 제공된 정보를 기반으로 질문에 대한 답변 추출
- 입력 텍스트에서 새 문장 생성: 텍스트를 다른 언어로 번역, 텍스트 요약
그러나 NLP는 서면 텍스트에만 국한되지 않는다. 음성 샘플의 대본 생성이나 이미지 설명 생성 등 음성 인식 및 컴퓨터 비전 분야의 복잡한 과제도 해결할 수 있다.
대규모 언어 모델(LLM)의 떡상
최근 NLP 분야는 LLM에 의해 혁신적인 발전을 이루고 있다. GPT(Generative Pre-trained Transformer)와 Llama와 같은 아키텍처를 포함하는 모델들이 언어 처리에서 가능한 것들을 바꿔 놓았다.
LLM은 방대한 양의 텍스트 데이터를 기반으로 학습된 AI 모델이다. 인간과 유사한 텍스트를 이해 및 생성하고, 언어의 패턴을 인식하며, 특정 작업에 대한 학습 없이도 다양한 언어 작업을 수행할 수 있다. 이는 NLP 분야에서 중요한 발전이다.
LLM의 특징은 다음과 같다.
- 규모: 수백만, 수십억, 수천억 개의 매개변수를 포함한다.
- 보편성: 특정 작업에 대한 훈련 없이도 여러 작업을 수행할 수 있다.
- 맥락 내 학습(In-context learning): 프롬프트에 제공된 예시를 통해 학습할 수 있다.
- 창발 능력: 모델의 규모가 커짐에 따라, 명시적으로 프로그래밍되었거나 예상되지 않았던 능력을 발휘한다.
LLM의 등장은 특정 NLP 작업을 위해 특화 모델을 구축하는 것에서부터 시작되어 광범위한 언어 작업을 처리하도록 프롬프트되거나 파인튜닝될 수 있는 단일 대규모 모델을 사용하는 것으로 전환되었다. 이로 인해 정교한 언어 처리가 더 쉽게 접근 가능해졌지만 효율성, 윤리, 배포와 같은 영역에서 새롭게 해결해야 하는 과제들이 생겨났다.
또, LLM에는 다음과 같은 중요한 한계들이 존재한다.
- 할루시네이션: 잘못된 정보를 자신 있게 생성할 수 있다.
- 진정한(true) 이해 부족: 세상에 대한 진정한 이해가 부족하고 순수하게 통계적 패턴에만 의존한다.
- 편향(bias): 훈련 데이터나 입력에 존재하는 편향을 재현할 수 있다.
- 맥락 범위(context windows): 제한된 맥락 범위를 가진다(하지만 개선되고 있다).
- 계산 리소스: 상당한 계산 리소스를 필요로 한다.
언어 처리가 어려운 이유
컴퓨터는 인간과 같은 방식으로 정보를 처리하지 않는다.
예를 들어 "나는 배고프다"라는 문장을 읽으면 그 의미를 쉽게 이해할 수 있다. 비슷하게 우리는 "나는 배고프다"와 "나는 슬프다"라는 두 문장이 얼마나 유사한지 쉽게 판단할 수 있다. 머신러닝 모델의 경우, 이러한 작업은 어렵다. 모델이 학습할 수 있도록 텍스트를 처리해야 한다. 그리고 언어는 복잡하기 때문에 처리 방식을 신중하게 생각해야 한다.
LLM의 발전에도 불구하고 여전히 많은 근본적인 과제가 남아 있다. 여기에는 모호성, 문화적 맥락, 풍자, 유머를 이해하는 것이 포함된다. LLM은 다양한 데이터셋에 대한 대규모 학습을 통해 이러한 과제를 해결하지만, 여전히 여러 복잡한 상황에서 인간 수준의 이해에는 미치지 못하는 경우가 많다.
1.3 Transformer 모델이 할 수 있는 것
이 섹션에서는 Transformers 라이브러리의 `pipeline()` 함수를 사용해 Transformer 모델이 할 수 있는 것에 대해 살펴본다.
Transformer is everywhere
트랜스포머 모델은 자연어 처리, 컴퓨터 비전, 오디오 처리 등 다양한 모달에서 모든 종류의 작업을 해결하는 데 사용된다.
Hugging Face와 트랜스포머 모델을 사용하고 모델을 공유함으로써 커뮤니티에 기여하고 있는 회사는 Google AI, Facebook AI, Microsoft, Grammarly 등이 있다.
Transformers 라이브러리는 이와 같은 공유된 모델을 생성하고 사용할 수 있게 해 준다. Model Hub는 누구나 다운로드하여 사용할 수 있는 수백만 개의 pre-trained 모델이 존재한다. 업로드 또한 가능하다. (트랜스포머 모델에 국한된 것이 아니고 모든 종류의 모델이나 데이터셋을 공유할 수 있다.)
파이프라인 사용하기
Transformers 라이브러리에서 가장 기본적인 객체는 `pipeline()` 함수이다. 이 함수는 모델을 전처리 및 후처리 단계와 연결하여 사용자가 텍스트를 직접 입력하고 이해할 수 있는 결과를 얻을 수 있게 해 준다.
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier("Finally my summer session is over. I am free.")[{'label': 'POSITIVE', 'score': 0.9952530860900879}]
여러 개의 문장을 넣을 수도 있다:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier(
["Finally my summer session is over. I am free.", "I'm starving."]
)[{'label': 'POSITIVE', 'score': 0.9952530860900879},
{'label': 'NEGATIVE', 'score': 0.9996090531349182}]
디폴트로, 이 파이프라인은 영어의 감정 분석을 위해 파인튜닝된 특정한 pretrained 모델을 선택한다. classifier 객체를 생성할 때 모델이 다운로드되고 캐싱된다. 명령어를 다시 실행하면, 캐싱된 모델이 대신 사용되므로 모델을 다시 다운받을 필요가 없다.
텍스트를 파이프라인에 넘길 때 거치는 주요 3단계:
- 텍스트는 모델이 이해할 수 있는 포맷으로 전처리된다.
- 전처리된 입력이 모델에 전달된다.
- 모델의 예측은 후처리되어, 사람이 이해할 수 있게 된다.
다양한 모달리티에 사용 가능한 파이프라인들
`pipeline()` 함수는 다양한 모달리티를 지원함으로써 텍스트, 이미지, 오디오, 심지어 멀티모달 작업들까지 수행할 수 있도록 해 준다. 이 코스는 텍스트 작업에 초점을 맞추지만, 트랜스포머 아키텍처의 포텐셜을 이해하는 것은 중요하므로 간단히 짚고 넘어가자.
가능한 작업에 대한 오버뷰는 다음과 같다:
전체 파이프라인 목록은 여기: 🤗 Transformers documentation
Text 파이프라인
- `text-generation`: 프롬프트로부터 텍스트 생성
- `text-classification`: 사전 정의된 카테고리로 텍스트 분류
- `summarization`: 핵심 정보는 보존하면서 텍스트의 짧은 버전 생성
- `translation`: 텍스트를 다른 언어로 번역
- `zero-shot-classification`: 특정한 레이블에 대한 우선적 학습 없이 텍스트 분류
- `feature-extraction`: 텍스트의 벡터 표현 추출
Image 파이프라인
- `image-to-text`: 이미지의 텍스트 설명 생성
- `image-classification`: 이미지에서 객체 식별
- `object-detection`: 이미지들에서 객체를 찾아 식별
Audio 파이프라인
- `automatic-speech-recognition`: 스피치를 텍스트로 변환
- `audio-classification`: 오디오를 카테고리로 분류
- `text-to-speech`: 텍스트를 오디오로 변환
Multimodal 파이프라인
- `image-text-to-text`: 텍스트 프롬프트 기반으로 이미지에 반응
Zero-shot classification
레이블이 지정되지 않은 텍스트를 분류하는 작업이다.
텍스트에 주석을 달면 시간이 많이 소요되고 해당 분야의 전문지식이 필요하기 때문에 실제 프로젝트에서 흔히 발생하는 상황이다. 이런 경우 제로샷 분류 파이프라인은 매우 강력하다. 분류에 사용할 레이블을 지정할 수 있기 때문에, 사전 학습된 모델의 레이블에 의존하지 않아도 된다.
모델이 두 레이블을 사용하여 문장을 `POSITIVE` 혹은 `NEGATIVE`로 분류하는 방법을 앞서 살펴보았다. 다른 레이블 집합을 사용한 텍스트도 분류할 수 있다.
from transformers import pipeline
classifier = pipeline("zero-shot-classification")
classifier(
"I learned 'Automata and Formal Languages' from summer session.",
candidate_labels=["education", "politics", "business"],
){'sequence': "I learned 'Automata and Formal Languages' from summer session.",
'labels': ['education', 'business', 'politics'],
'scores': [0.8539456129074097, 0.12987299263477325, 0.016181396320462227]}
제로샷이라고 불리는 이유는, 모델을 사용하기 위해 내 데이터로 파인튜닝할 필요가 없기 때문이다.
원하는 아무 레이블 목록에 대해 직접적으로 확률 점수를 리턴해 준다.
Text generation
파이프라인을 사용해 텍스트를 생성하는 방법이다.
핵심은 프롬프트를 입력하면 모델이 나머지 텍스트를 생성해 프롬프트를 자동 완성한다는 것이다.
이는 많은 휴대폰에서 제공되는 예측 텍스트 기능(자동완성)과 유사하다. 텍스트 생성에는 무작위성이 포함되므로 항상 같은 결과가 나오지는 않는다.
from transformers import pipeline
generator = pipeline("text-generation")
generator("I skipped my breakfast and now I'm starving. I've gotta")[{'generated_text': "I skipped my breakfast and now I'm starving. I've gotta get some water, and I'll have to get some food. I can't eat and I'm exhausted. I'm a kid and I'm running out of food… I'm just kind of running out of food. I feel like I've got to give the kids something. I feel like I'm trying to get them some food. I feel like I'm trying to get them some food. I feel like I'm trying to get food. I feel like I'm trying to get food. I feel like I'm trying to get food. I feel like I'm trying to get food. I feel like I'm trying to get food. I feel like I'm trying to get food. I feel like I'm trying to get food. I feel like I'm trying to get food. I feel like I'm trying to get food. I feel like I'm trying to get food. I feel like I'm trying to get food. I feel like I'm trying to get food. I feel like I'm trying to get food. I feel like I'm trying to get food. I feel like I'm trying to get food. I feel like I'm trying to get food. I feel like I'm trying to get food. I feel like I'm trying"}]
인수 `num_return_sequences`로 생성되는 시퀀스의 수를 조절할 수 있고,
인수 `max_length`로 출력 텍스트의 총 길이를 제어할 수 있다.
from transformers import pipeline
generator = pipeline("text-generation", num_return_sequences=2, max_length=15)
generator("I skipped my breakfast and now I'm starving. I've gotta")[{'generated_text': "I skipped my breakfast and now I'm starving. I've gotta spend the rest of the day just trying to survive. Oh, and then go home and watch the movies. Now I'm starving! This one is gonna be my last.\n\n"},
{'generated_text': 'I skipped my breakfast and now I\'m starving. I\'ve gotta eat a lot, so I\'ll probably try to eat more before the train gets here, and that\'ll be good for me.\n\n"I\'ve got a lot of time on'}]
파이프라인에 Hub의 모델 사용하기
앞선 예제에서는 디폴트 모델을 사용했지만, Hub에서 특정 모델을 선택하여 특정 작업의 파이프라인에 사용할 수도 있다.
(예: 텍스트 생성 - Model Hub에서 왼쪽의 태그를 클릭하면 해당 작업을 지원하는 모델만 표시된다)
`HuggingFaceTB/SmolLM2-360M` 모델을 사용해 보자. 전과 같은 파이프라인에 로드하는 방법은 다음과 같다:
from transformers import pipeline
# 방법 1: pipeline에서 설정 (기본값)
generator = pipeline("text-generation", num_return_sequences=2, max_length=15, model="HuggingFaceTB/SmolLM2-360M")
generator("텍스트1")
# 방법 2: generator 호출할 때마다 설정 (일회성)
generator = pipeline("text-generation", model="HuggingFaceTB/SmolLM2-360M")
generator(
"텍스트1",
max_length=10,
num_return_sequences=2,
)[{'generated_text': 'In this course, we will teach you how to make your own digital money'},
{'generated_text': 'In this course, we will teach you how to do that and more.'}]
언어 태그를 클릭해서 모델을 검색하고 다른 언어로 텍스트를 생성하는 모델을 선택할 수도 있다.
Model Hub는 여러 언어를 지원하는 다국어 모델에 대한 체크포인트도 있다. 모델을 클릭해서 선택하면, 온라인에서 바로 체험해볼 수 있는 위젯이 표시된다. 이런 방식으로, 모델을 다운받기 전에 기능을 빠르게 테스트하는 것이 가능하다.
Mask filling
다음으로 `fill-mask` 파이프라인을 살펴보자.
이 작업은 주어진 텍스트의 빈칸을 채우는 것이다.
from transformers import pipeline
unmasker = pipeline("fill-mask")
unmasker("I'm having an grande-sized iced americano and some <mask> at starbucks.", top_k=2)[{'score': 0.11658336967229843,
'token': 3895,
'token_str': ' coffee',
'sequence': "I'm having an grande-sized iced americano and some coffee at starbucks."},
{'score': 0.0819304808974266,
'token': 26639,
'token_str': ' popcorn',
'sequence': "I'm having an grande-sized iced americano and some popcorn at starbucks."}]
`top_k` 인수는 표시될 확률의 개수를 조절한다.
여기서 모델은 mask token이라고 하는 특별한 `<mask>` 단어를 채운다. 다른 마스킹 채우기 모델은 다른 마스크 토큰을 가질 수 있으므로, 항상 올바른 마스크 단어를 확인해야 한다. 위젯에 사용된 마스크 단어를 보고 확인하는 방법도 있다.
개체명 인식(NER)
개체명 인식(Named Entity Recognition)은 모델이 입력 텍스트의 어떤 부분이 사람(`PER`), 위치(`LOC`), 조직(`ORG`)과 같은 개체에 해당하는지 찾아내는 작업이다.
from transformers import pipeline
ner = pipeline("ner", grouped_entities=True)
ner("My name is Mia and I go to Ewha Womans University in Sinchon.")[{'entity_group': 'PER',
'score': np.float32(0.99887484),
'word': 'Mia',
'start': 11,
'end': 14},
{'entity_group': 'ORG',
'score': np.float32(0.99853724),
'word': 'Ewha Womans University',
'start': 27,
'end': 49},
{'entity_group': 'LOC',
'score': np.float32(0.9821436),
'word': 'Sinchon',
'start': 53,
'end': 60}]
파이프라인 생성 함수에 `grouped_entities=True` 옵션을 전달하면, 파이프라인이 동일한 개체에 해당하는 문장 부분들을 다시 그룹화하도록 한다.
이 경우 모델은 "Hugging"과 "Face"라는 이름이 여러 단어로 구성되어 있어도 하나의 조직으로 올바르게 그룹화했다.
다음 챕터에서 살펴보겠지만, 전처리 과정에서 일부 단어는 더 작은 부분으로 나뉜다.
예를 들어 "Sylvain"은 전처리 단계에서 S, ##yl, ##va, ##in의 4부분으로 쪼개진다. 후처리 단계에서 파이프라인이 이 부분들을 그룹화한다.
Question answering
`question-answering` 파이프라인은 주어진 문맥의 정보를 사용해서 질문에 답한다.
from transformers import pipeline
question_answerer = pipeline("question-answering")
question_answerer(
question="Where am I?",
context="I'm having a tomato basil bagel at starbucks in Sinchon.",
){'score': 0.37248334288597107, 'start': 48, 'end': 55, 'answer': 'Sinchon'}
이 파이프라인은 주어진 문맥으로부터 정보를 추출하는 식으로 작동한다. 답을 생성하는 것이 아니다.
요약
`summarization` 파이프라인은 텍스트에서 언급된 모든(혹은 대부분의) 중요한 측면을 그대로 유지하면서 텍스트를 더 짧게 줄인다.
from transformers import pipeline
summarizer = pipeline("summarization")
summarizer(
"""
To cook Jjapaghetti (also spelled Chapagetti), you'll need the instant noodle package, and optionally, some water and a pan.
First, boil water in a pot.
Add the noodles and vegetable flakes from the Jjapaghetti package.
Cook until the noodles are soft, usually around 4-5 minutes.
Drain most of the water, leaving about 1/4 cup.
Add the sauce powder and oil from the Jjapaghetti packets, and stir everything together until the noodles are well-coated.
Serve immediately. You can customize it with a fried egg, or other toppings if desired.
"""
)[{'summary_text': " To cook Jjapaghetti (also spelled Chapagetti), you'll need the instant noodle package, some water and a pan . Cook until the noodles are soft, usually around 4-5 minutes . You can customize it with a fried egg, or other toppings if desired ."}]
`text-generation` 처럼, `max_length`나 `min_length`를 명시할 수 있다.
번역
번역 작업의 경우, 작업(task) 이름에 언어 쌍(예: `"translation_en_to_fr"`)을 입력하면 디폴트 모델을 사용할 수 있다. 하지만 가장 쉬운 방법은 Model Hub에서 사용할 모델을 선택하는 것이다.
`Helsinki-NLP/opus-mt-ko-en` 모델을 활용해 한-영 번역을 해 보자.
from transformers import pipeline
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-ko-en")
translator("누군가 방금 스타벅스 계단을 올라오다가 음료를 쏟았다.")[{'translation_text': 'Someone just came up thestrucks stairs and spilled their drinks.'}]
`text-generation`과 `summarization`처럼, `max_length`나 `min_length`를 명시할 수 있다.
Image와 Audio 파이프라인
`image-classification` 파이프라인 예제:
from transformers import pipeline
image_classifier = pipeline(
task="image-classification", model="google/vit-base-patch16-224"
)
result = image_classifier(
"https://i.etsystatic.com/42736016/r/il/c36b6d/5421454147/il_570xN.5421454147_evra.jpg"
)
print(result)[{'label': 'schipperke', 'score': 0.24917517602443695}, {'label': 'Egyptian cat', 'score': 0.1983620822429657}, {'label': 'groenendael', 'score': 0.06979704648256302}, {'label': 'book jacket, dust cover, dust jacket, dust wrapper', 'score': 0.06294012069702148}, {'label': 'bookcase', 'score': 0.04791552945971489}]
`automatic-speech-recognition` 파이프라인 예제:
from transformers import pipeline
transcriber = pipeline(
task="automatic-speech-recognition", model="openai/whisper-large-v3"
)
result = transcriber(
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac"
)
print(result){'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
여러 소스의 데이터 결합
여러 소스의 데이터를 결합하고 처리하는 것은 트랜스포머 모델의 강력한 활용 사례 중 하나이다. 다음과 같은 경우에 유용하게 사용할 수 있다:
- 여러 데이터베이스 또는 리포지토리 검색
- 다양한 포맷(텍스트, 이미지, 오디오)의 정보 통합
- 관련 정보에 대한 통합된 뷰 생성
예를 들어 이런 시스템을 구축할 수 있다:
- 텍스트 및 이미지 같은 멀티모달 데이터베이스에서 정보 검색
- 다양한 소스의 결과(예: 오디오 파일과 텍스트 설명)를 하나의 일관된 응답으로 결합
- 문서 및 메타데이터 데이터베이스에서 가장 관련성 높은 정보 제공
결론
이 챕터에서 살펴본 파이프라인은 대부분 설명 목적으로만 사용된다. 특정 작업을 위해 프로그래밍되었으며 그 작업의 베리에이션을 수행할 수는 없다.
다음 챕터에서 `pipeline()` 함수의 내부 구조와 동작을 커스터마이징하는 방법을 알아보자.
Transformer의 작동 원리
이 섹션에서는 트랜스포머 모델의 아키텍처를 살펴보고 어텐션과 인코더-디코더 아키텍처의 개념에 대해 딥다이브한다.
Transformer 역사
트랜스포머 아키텍처는 2017년 6월에 처음 소개되었다. 초기 연구는 번역 작업에 중점을 두었는데, 이후 다음과 같은 여러 모델이 등장했다.
- 2018.06: GPT(최초의 사전 학습된 트랜스포머 모델). 다양한 NLP 작업의 파인튜닝에 사용되어 SOTA 결과를 얻었다.
- 2018.10: BERT. 문장 요약을 더 잘 생성하도록 설계
- 2019.02: GPT-2. GPT의 개선된, 더 큰 버전
- 2019.10: T5. 시퀀스-투-시퀀스 트랜스포머 아키텍처의 멀티태스킹 중심 구현
- 2020.05: GPT-3. 파인튜닝 없이도 다양한 작업을 수행(제로샷 학습)
- 2022.01: InstructGPT. 지시를 더 잘 따르도록 훈련된 GPT-3 버전
- 2023.01: Llama. 다양한 언어에서 텍스트를 생성
- 2023.03: Mistral. 모든 평가 기준에서 Llama 2 13B보다 우수한 성능을 보이는 70억 개의 파라미터를 가진 언어 모델
- 2024.03: Gemma 2. 20~270억 개의 파라미터를 가지는 가벼운 SOTA 오픈 모델
- 2024.11: SmolLM2. 1억 3,500만~17억 개의 파라미터를 가지는 SOTA 소형 언어 모델
- GPT-like (auto-regressive 트랜스포머 모델)
- BERT-like (auto-encoding 트랜스포머 모델)
- T5-like (seq2seq 트랜스포머 모델)
트랜스포머는 언어 모델이다
위에서 언급한 모든 트랜스포머 모델은 언어 모델로 트레이닝되었다. 즉, 이 모델들은 대량의 raw 텍스트를 self-supervised 방식으로 학습했다. Self-supervised 학습은 모델의 입력값에서 목표(objective)가 자동으로 계산되는 학습 유형으로, 사람이 데이터를 라벨링할 필요가 없다.
이러한 모델은 훈련된 언어에 대한 통계적인 이해를 가지고는 있지만, 특정한 실무 작업에는 그닥 유용하지 않다. 따라서 일반적으로 pretrained 모델은 전이학습(transfer learning) 또는 파인튜닝이라는 프로세스를 거친다. 이 과정에서 모델은 사람이 주석을 단 레이블을 사용하는 supervised 방식으로 파인튜닝된다.
그러한 작업의 예로, 이전 n개의 단어를 읽고 문장의 다음 단어를 예측하는 것이 있다. 이는 출력이 과거와 현재 입력값에 따라 달라지지만, 미래의 입력값에는 영향을 받지 않기 때문에 인과적 언어 모델링(casual language modeling)이라고 한다.

또다른 예는 마스킹된 언어 모델링(masked language modeling)으로, 모델이 문장에서 마스킹된 단어를 예측한다.

트랜스포머는 큰 모델이다
DistilBERT 같은 몇몇 예외를 제외하면, 더 좋은 성능을 얻기 위한 일반적인 전략은 모델의 사이즈와 모델이 사전 학습되는 데이터의 양을 증가시키는 것이다.

큰 모델을 학습시키는 건 많은 양의 데이터를 필요로 한다. 이는 시간과 계산 리소스 차원에서 아주 비싸진다. 심지어는 환경 문제를 일으키기도 한다(미국에서 자동차가 한평생 배출하는 이산화탄소의 양보다 최첨단 LM이 BigScience 프로젝트에서 2천억 개의 파라미터를 학습하면서 배출하는 이산화탄소 양이 더 많았다). 최적의 파라미터를 찾기 위해 많은 시도를 한다는 것을 생각하면 배출량은 훨씬 높을 것이다.
이 때문에 언어 모델을 공유하는 것은 매우 중요하다. 훈련된 가중치를 공유하고, 이미 훈련된 가중치를 기반으로 모델을 구축하면 전체 계산 비용과 전체적인 탄소 발자국을 줄일 수 있다.
참고로 모델 훈련의 탄소 발자국을 평가할 수 있다. Transformers 라이브러리에 통합된 ML CO2 Impact나 Code Carbon 도구를 사용하면 된다.
전이 학습 (Transfer Learning)
사전 학습(pretraining)은 모델을 처음부터 학습시키는 것이다. 가중치는 랜덤으로 초기화되고, 학습은 어떤 사전 지식도 없이 시작된다. 이러한 사전 학습은 일반적으로 매우 방대한 양의 데이터를 기반으로 수행된다. 따라서 매우 방대한 양의 데이터가 필요하며, 학습에는 최대 몇 주가 소요될 수 있다.
반면 파인튜닝은 모델이 사전 학습된 후에 수행되는 학습이다. 파인튜닝을 수행하려면, 사전 학습된 언어 모델을 확보하고, 나의 task에 특화된 데이터셋을 사용해 추가 학습을 수행한다.
처음부터 모델을 나의 최종 유즈케이스에 맞춰 학습시키는 게 더 간단할 텐데, 왜 그러지 않을까? 몇 가지 이유가 있다.
- 사전 학습된 모델은 파인튜닝 데이터셋과 비슷한 데이터셋으로 이미 학습된 상태이다. 파인튜닝 프로세스는 사전 학습 과정에서 초기 모델이 습득한 지식(예: NLP 문제의 경우 사전 학습된 모델은 task에 사용하는 언어에 대한 통계적 이해를 갖게 됨)을 활용할 수 있다.
- 사전 학습된 모델은 이미 많은 양의 데이터로 학습되었기 때문에, 파인튜닝에 필요한 데이터는 훨씬 적다.
- 같은 이유로, 좋은 결과를 얻기 위해 필요한 시간과 자원의 양이 훨씬 적다.
사전 학습된 모델이 습득한 지식은 "전이"되므로, 전이 학습이라고 한다.
그러므로, 모델을 파인튜닝하면 시간, 데이터, 재정적, 환경적 비용을 절감할 수 있다. 또한 전체 사전 학습보다 학습에 제약이 적어 다양한 파인튜닝 방식을 반복하는 것이 더 빠르고 쉽다. 이 과정은 (데이터가 많지 않은 경우) 처음부터 학습하는 것보다 더 나은 결과를 얻을 수 있다. 따라서 항상 사전 학습된 모델, 그 중 나의 task와 가능한 가장 가까운 모델을 파인튜닝하는 것이 좋다.
일반적인 트랜스포머 아키텍처
트랜스포머 모델의 일반적인 아키텍처를 살펴보자.
모델은 주로 2개의 블록으로 이루어져 있다.
- Encoder(왼쪽): 입력을 받고 입력의 표현을 구축(feature)한다. 즉 모델은 입력으로부터 이해를 얻도록 최적화된다.
- Decoder(오른쪽): 인코더의 표현(feature)을 사용해 목표 시퀀스를 생성한다. 즉 모델은 출력 생성에 최적화된다.
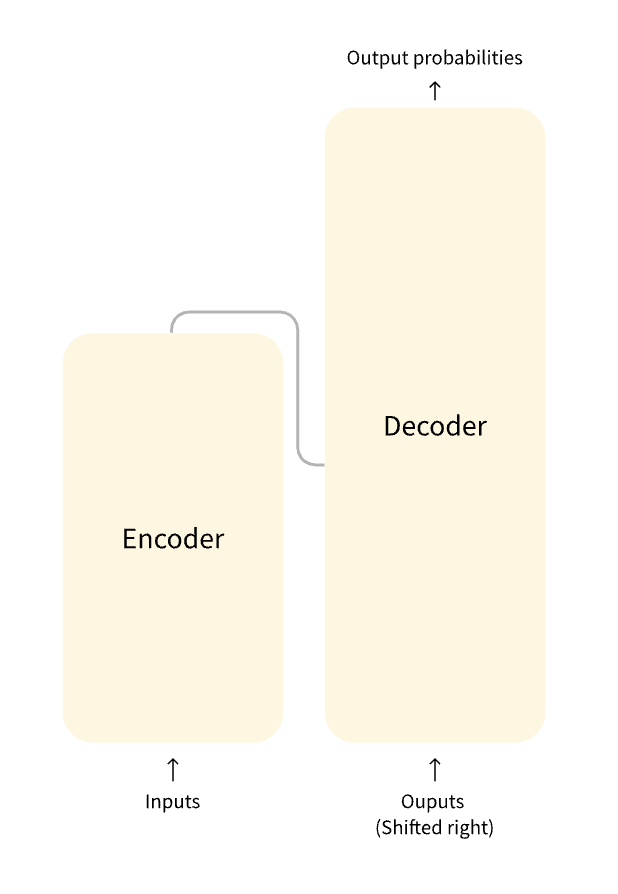
각 부분은 task에 따라 독립적으로 사용될 수 있다:
- Encoder-only 모델: 문장 분류 및 개체명 인식처럼 입력에 대한 이해가 필요한 작업에 적합
- Decoder-only 모델: 텍스트 생성과 같은 생성 작업에 적합
- Encoder-decoder 모델 혹은 sequence-to-sequence 모델: 번역, 요약과 같이 입력이 필요한 생성 작업에 적합
어텐션 레이어
트랜스포머 모델의 핵심 특징은 attention layers라고 불리는 특별한 레이어로 구축되었다는 것이다.
(트랜스포머 아키텍처를 소개하는 논문의 제목은 "Attention is All You Need!"였다.)
이 레이어는 모델에게 각 단어의 표현을 처리할 때 문장의 특정한 단어에 주의를 기울이라고 한다.
영어에서 프랑스어로 텍스트를 번역하는 작업을 생각해 보자.
"You like this course"라는 입력이 주어졌을 때, 번역 모델은 "like"라는 단어를 적절하게 번역하기 위해 인접 단어 "You"에도 주의를 기울여야 한다. 프랑스어에서 "like" 동사는 주어에 따라 형태가 다르기 때문이다. 그러나 문장의 나머지 부분은 해당 단어의 번역에 딱히 쓸모가 없다.
마찬가지로, "this"를 번역할 때 모델은 "course"라는 단어에도 주의를 기울여야 한다. "this"는 연관된 명사가 남성인지 여성인지에 따라 다르게 번역되기 때문이다. 다른 단어들은 "course"의 번역에 중요하지 않다. 더 복잡한 문장과 문법 규칙의 경우, 모델은 각 단어를 정확하게 번역하기 위해 문장에서 더 멀리 나타날 수 있는 단어에 특히 주의를 기울여야 한다.
자연어와 관련된 모든 작업에 동일한 개념이 적용된다. 단어 자체는 의미를 가지지만 그 의미는 맥락에 따라 크게 영향을 받는데, 여기서 맥락이란 학습하는 단어의 앞뒤에 있는 다른 단어들일 수 있다.
이제 어텐션 레이어가 뭔지 대충 알았으니 트랜스포머 아키텍처를 더 자세히 살펴보자.
원래 아키텍처
Transformer 아키텍처는 원래 번역을 위해 설계되었다. 학습 과정에서 인코더는 특정 언어로 입력(문장)을 받는 반면, 디코더는 원하는 목표 언어로 동일한 문장을 받는다. 인코더에서 어텐션 계층은 문장의 모든 단어를 사용할 수 있다(방금 살펴본 바와 같이 단어의 번역은 문장의 앞뒤 단어에 따라 달라질 수 있기 때문이다). 그러나 디코더는 순차적으로 작동하며 이미 번역이 끝난 문장의 단어(즉, 현재 생성 중인 단어의 앞 단어)에만 주의를 기울일 수 있다. 예를 들어, 처음 세 단어를 예측하면 우리는 이를 디코더에 전달하고, 디코더는 인코더의 모든 입력을 사용하여 네 번째 단어를 예측한다.
학습 속도를 높이기 위해, 디코더에 전체 목표 단어가 입력되지만 미래의 단어는 사용할 수 없다. 예를 들어, 네 번째 단어를 예측하려고 할 때, 어텐션 계층은 1번부터 3번까지의 단어에만 접근할 수 있다. 원래의 트랜스포머 아키텍처는 다음과 같았다. 왼쪽에는 인코더, 오른쪽에는 디코더가 있다.

디코더 블록의 첫 번째 어텐션 레이어는 디코더에 대한 모든 입력에 주의를 기울이는 반면, 두 번째 어텐션 레이어는 인코더의 출력을 사용한다. 따라서 전체 입력 문장에 접근해 현재의 단어를 가장 잘 예측할 수 있다. 이는 언어마다 단어의 순서를 다르게 지정하는 문법 규칙이 있거나, 문장 뒷부분에 제공된 맥락이 주어진 단어의 가장 적절한 번역을 결정하는 데 도움이 될 수 있으므로 매우 유용하다.
어텐션 마스크는 인코더/디코더에서 모델이 특정 단어에 주의를 기울이지 않도록 하는 데에도 사용될 수 있다. 예를 들자면 문장을 일괄 처리할 때 모든 입력의 길이를 동일하게 만드는 데 사용되는 특수 패딩 단어가 있다.
아키텍처 vs. 체크포인트
트랜스포머 모델을 공부하다 보면 모델만큼이나 아키텍처와 체크포인트에 대한 언급을 볼 수 있다. 이러한 용어는 모두 약간씩 다른 의미를 지닌다.
- 아키텍처: 모델의 골격, 즉 각 계층과 모델 내에서 발생하는 각 연산의 정의
- 체크포인트: 주어진 아키텍처에 로드되는 가중치
- 모델: "아키텍처"나 "체크포인트"만큼 정확하지는 않지만, 둘 다 의미할 수 있는 포괄적인 용어. 이 과정에서는 모호성을 줄이기 위해 아키텍처 또는 체크포인트를 명시한다.
예를 들어, BERT는 아키텍처이고, Google 팀이 BERT 첫 번째 릴리스를 위해 학습시킨 가중치 집합인 `bert-base-cased`는 체크포인트이다. 하지만 "BERT 모델"과 "`bert-base-cased` 모델"이라고 부르는 것도 가능하다.
'𝐄𝐰𝐡𝐚 > 𝐄-𝐂𝐎𝐏𝐒' 카테고리의 다른 글
| AWS EventBridge 기반 보안 이벤트 오케스트레이션 구현하기 (0) | 2025.11.23 |
|---|---|
| AWS GuardDuty IAM finding 타입 23개 정리 (1) | 2025.10.03 |
| 🍀 5월 3주차 TWIL (0) | 2025.05.26 |
| 번역 (0) | 2025.05.20 |
| 🍀5월 2주차 TWIL (0) | 2025.05.20 |