들어가며
전통주 추천 앱 '주전부리'를 개발하면서 리뷰 시스템을 구현했습니다.
사용자가 전통주에 별점과 후기를 남기고, 이미지도 첨부할 수 있는 기능입니다.
겉보기엔 간단해 보이지만 막상 만들어보니 고려할 게 많더라구요.
- 한 사용자가 같은 전통주에 리뷰를 여러 개 작성하면?
- 전통주 상세 페이지에서 평균 별점을 어떻게 효율적으로 계산할까?
- 이미지는 어디에 저장할까?
- 전통주는 숫자 ID를 쓰는데 리뷰는 ObjectId를 쓴다면?
이 글에서는 이런 문제들을 어떻게 해결했는지, 실제 코드와 함께 공유하려고 합니다.
구현할 기능:
- User/Alcohol/Review MongoDB 스키마 설계
- 복합 유니크 인덱스로 중복 리뷰 방지
- 리뷰 CRUD API (작성, 조회, 수정, 삭제)
- AWS S3 이미지 업로드
- Aggregation Pipeline으로 평균 별점 계산
전체 코드는 https://github.com/Hanrann6/Jujeonboori에 있습니다.
사전 준비
- Node.js와 npm 설치
- MongoDB 설치 (또는 MongoDB Atlas 계정)
- AWS S3 버킷
Part 1: MongoDB 스키마 설계
1.1 전체 구조 이해하기
리뷰 시스템은 세 개의 컬렉션(테이블)으로 구성됩니다.
User (사용자)
↓ author
Review (리뷰)
↓ alcohol
Alcohol (전통주)
Review가 중심에 있고, User와 Alcohol을 참조하는 구조예요.
SQL로 치면 외래키(Foreign Key) 관계와 비슷합니다.
1.2 User 스키마
먼저 `user.model.js` 파일을 만들어요.

필드 설명:
- nickname: 사용자가 설정하는 닉네임 (선택 사항)
- email: OAuth에서 받아온 이메일
- provider, providerId: 어떤 OAuth를 통해 가입했는지 (Google/Kakao)
- status: 탈퇴 처리용 (탈퇴해도 DB에서 삭제하지 않고 'deleted'로 표시)
1.3 Alcohol 스키마 - 숫자 ID와 ObjectId
`alcohol.model.js` 파일:

전통주 데이터는 크롤링해서 CSV로 관리했는데, 여기에 이미 1, 2, 3... 같은 index가 있었어요.
본격적인 개발 전 API 명세서를 작성할 때 이 숫자를 그대로 사용하기로 결정했었습니다.
index: { type: Number, unique: true } // 1, 2, 3, 4...
그런데 MongoDB는 기본적으로 _id라는 ObjectId를 자동으로 만들거든요:
_id: ObjectId("507f1f77bcf86cd799439011") // MongoDB가 자동 생성
그래서 두 개가 공존하게 됐어요:
- index: 사용자 친화적인 숫자 (API URL에 사용)
- _id: MongoDB ObjectId (내부 참조용)
왜 이렇게 됐냐면...😭
API 명세서를 작성할 때는 단순하게 생각했어요:
- 전통주 조회: GET /alcohols/123
- 리뷰 작성: POST /alcohols/123/reviews
숫자가 깔끔하니까 이렇게 정했죠. 근데 나중에 리뷰를 만들 때 문제가 생겼어요. 리뷰는 동적으로 생성되니까 1, 2, 3... 같은 순차 인덱스를 부여할 수가 없더라구요.
그래서:
- 전통주(Alcohol)는 숫자 index 사용
- 리뷰(Review)는 ObjectId 사용
이렇게 하이브리드로 가게 됐습니다.
1.4 Review 스키마
`review.model.js` 파일:

핵심 개념은 다음과 같습니다.
1) ObjectId 참조
author: {
type: mongoose.Schema.Types.ObjectId,
ref: 'User'
}
이게 뭐냐면, author 필드에는 User의 _id 값이 저장돼요. 예를 들어:
{
_id: ObjectId("abc123"),
author: ObjectId("user001"), // User 컬렉션의 _id
alcohol: ObjectId("alcohol001"), // Alcohol 컬렉션의 _id
rating: 5,
content: "정말 맛있어요!"
}
나중에 populate()라는 기능을 쓰면 ObjectId 대신 실제 User 정보를 가져올 수 있어요. (SQL의 JOIN과 비슷)
2) 복합 유니크 인덱스

이 한 줄이 정말 중요해요. 이게 뭐냐면:
- author(사용자)와 alcohol(전통주)의 조합이 유일해야 한다는 뜻
- 같은 사용자가 같은 전통주에 리뷰를 2개 작성하려고 하면 MongoDB가 에러를 냄
이라는 뜻입니다.
예시:
// ✅ 성공: user001이 alcohol001에 첫 리뷰
{ author: "user001", alcohol: "alcohol001", rating: 5 }
// ✅ 성공: user001이 alcohol002에 리뷰 (다른 전통주)
{ author: "user001", alcohol: "alcohol002", rating: 4 }
// ✅ 성공: user002가 alcohol001에 리뷰 (다른 사용자)
{ author: "user002", alcohol: "alcohol001", rating: 3 }
// ❌ 실패: user001이 alcohol001에 또 리뷰 (중복)
{ author: "user001", alcohol: "alcohol001", rating: 5 }
이 인덱스 덕분에 한 사용자가 같은 전통주에 리뷰를 여러 개 작성하는 걸 막을 수 있어요.
Part 2: 리뷰 작성 API
이제 본격적으로 리뷰를 작성하는 API를 만들어 보겠습니다.
2.1 전체 플로우
사용자가 리뷰를 작성하면 이런 순서로 처리돼요:
1. JWT 토큰 검증 (사용자 확인)
↓
2. 전통주가 존재하는지 확인
↓
3. 이미 리뷰를 작성했는지 확인 (중복 체크)
↓
4. 입력값 검증 (별점 1-5, 내용 필수)
↓
5. 이미지가 있으면 S3에 업로드
↓
6. Review 문서 생성 및 저장
↓
7. 응답 반환
2.2 숫자 ID를 ObjectId로 변환
가장 먼저 해야 할 일은 프론트엔드에서 받은 숫자 ID를 ObjectId로 변환하는 거예요.
`review.service.js`:

왜 이렇게 하냐면:
프론트엔드는 POST /alcohols/123/reviews로 요청해요. 여기서 123은 숫자죠.
근데 Review 스키마를 보면:
alcohol: {
type: mongoose.Schema.Types.ObjectId, // ObjectId여야 함!
ref: 'Alcohol'
}
그래서 먼저 Alcohol.findOne({ index: 123 })으로 찾아서, 그 문서의 _id(ObjectId)를 가져오는 거예요.
2.3 중복 리뷰 검증
다음은 이미 리뷰를 작성했는지 확인해요.

스키마에 유니크 인덱스가 있는데 왜 또 체크해야 하냐?
유니크 인덱스만 있으면 MongoDB가 에러를 내긴 하는데, 에러 메시지가 별로예요:
MongoError: E11000 duplicate key error collection
이건 사용자한테 보여줄 수 없죠. 그래서 서비스 레이어에서 먼저 체크해서 친절한 메시지를 만들었어요:
{
"status": 409,
"message": "이미 이 전통주에 대한 리뷰를 작성하셨습니다.",
"existingReviewId": "abc123"
}
existingReviewId까지 반환하면 프론트엔드에서 "수정하시겠습니까?" 같은 버튼을 보여줄 수 있어요.
2.4 입력값 검증

MongoDB 스키마에도 min: 1, max: 5 같은 검증이 있긴 한데, 제가 구현한 것처럼 서비스 레이어에서 먼저 체크하면:
- 더 명확한 에러 메시지
- 불필요한 DB 쿼리 방지
- 로직을 한곳에서 관리
여러 이점들이 있습니다.
2.5 리뷰 생성 및 저장
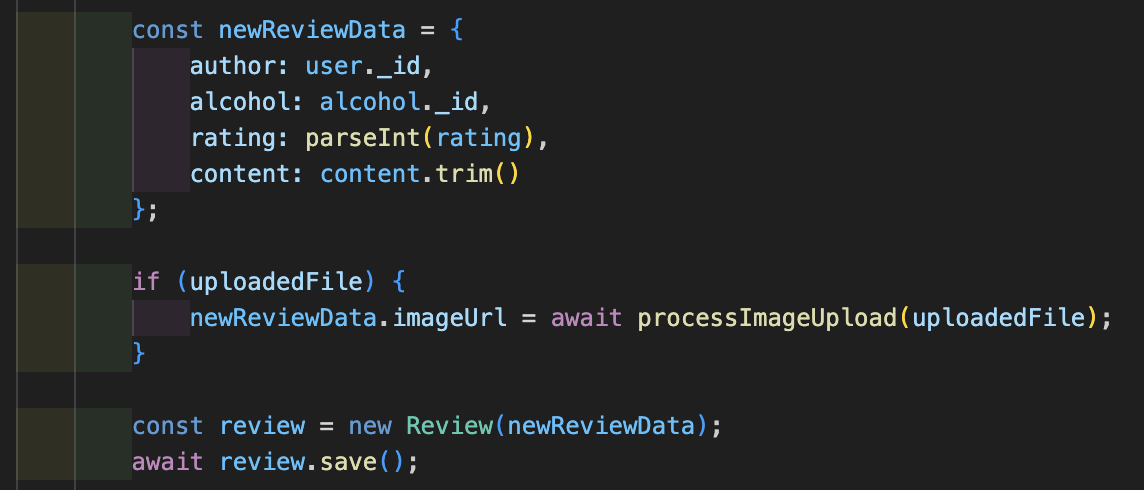
여기서 핵심은 ObjectId로 저장한다는 거예요:
{
_id: ObjectId("review123"),
author: ObjectId("user001"), // User의 _id
alcohol: ObjectId("alcohol456"), // Alcohol의 _id
rating: 5,
content: "정말 맛있어요!"
}
2.6 응답 데이터 구성
리뷰를 저장했으면 이제 응답을 만들어야겠죠. 근데 그냥 보내면:
{
"_id": "review123",
"author": "user001", // ObjectId만 있음
"alcohol": "alcohol456", // ObjectId만 있음
"rating": 5
}
이건 별로죠. 사용자 닉네임이랑 전통주 이름도 보여줘야 해요.
여기서 populate()가 등장합니다.

populate()는 SQL의 JOIN과 비슷해요. ObjectId를 실제 데이터로 채워줍니다.
// populate() 전
{
author: ObjectId("user001"),
alcohol: ObjectId("alcohol456")
}
// populate() 후
{
author: {
_id: "user001",
nickname: "홍길동"
},
alcohol: {
_id: "alcohol456",
alcoholName: "막걸리",
index: 123
}
}
두 번째 파라미터('nickname', 'alcoholName index')는 가져올 필드를 지정하는 거예요. 전체 다 가져오면 무거우니까요.
.lean()은 Mongoose 문서를 순수 JavaScript 객체로 변환해줍니다.
2.7 최종 응답

중요한 포인트:
alcohol_id: populatedReview.alcohol.index // 숫자로 반환
DB에는 ObjectId로 저장했지만, 응답할 때는 다시 숫자 index로 바꿔서 보내요. 프론트엔드가 숫자 ID를 기대하니까요.
Part 3: AWS S3 이미지 업로드
리뷰에 이미지를 첨부할 수 있어야 해요. 이미지는 서버 디스크가 아니라 AWS S3에 저장합니다.
3.1 왜 S3를 쓰나요?
서버 디스크에 저장하는 경우:
- 서버를 재시작하면 이미지 날아감
- 서버가 여러 대면 동기화 문제
- 용량 제한
S3를 쓰는 경우:
- 안정적인 클라우드 스토리지
- CDN과 연동 가능 (빠른 이미지 로딩)
- 확장성 좋음
따라서 저희 팀은 S3를 사용하기로 했습니다.
3.2 multer-s3 설정
multer는 파일 업로드를 처리하는 라이브러리고, multer-s3는 S3에 바로 업로드해주는 확장이에요.
코드 설명:
1) key 함수: S3에 저장될 파일 경로를 정해요

예를 들어 막걸리.jpg를 업로드하면:
- S3에 reviews/1735123456789_막걸리.jpg로 저장됨
- 타임스탬프를 붙여서 파일명 중복 방지
2) fileFilter: 허용할 파일 타입을 검사해요
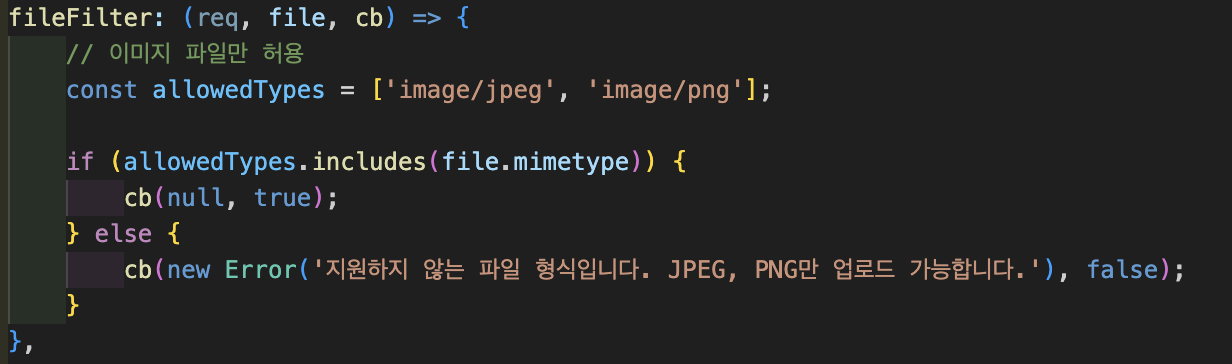
PDF나 동영상은 막히고, JPEG/PNG만 통과해요.
3) limits: 파일 크기 제한

5MB 넘는 파일은 자동으로 거부돼요.
3.3 라우트에 미들웨어 추가

미들웨어 순서가 중요해요:
- 먼저 JWT 검증 (로그인한 사용자인지)
- 이미지를 S3에 업로드
- 컨트롤러에서 리뷰 생성
`upload.single('image')`는 `image`라는 이름의 파일 하나를 처리한다는 뜻이에요.
프론트엔드에서 이렇게 보내야 합니다:
const formData = new FormData();
formData.append('rating', 5);
formData.append('content', '맛있어요');
formData.append('image', file); // 'image'라는 키!
3.4 업로드된 파일 사용하기
컨트롤러에 도착하면 `req.file`에 업로드 정보가 들어있어요:
{
fieldname: 'image',
originalname: '막걸리.jpg',
mimetype: 'image/jpeg',
size: 245678,
location: 'https://bucket-name.s3.region.amazonaws.com/reviews/1735123456789_막걸리.jpg'
}
우리가 필요한 건 `location` (S3 URL)이에요:
if (uploadedFile) {
newReviewData.imageUrl = uploadedFile.location;
}
이 URL을 DB에 저장하면 끝입니다!
Part 4: 전통주 상세 조회 + 평균 별점 계산
전통주 상세 페이지에서는 리뷰 개수랑 평균 별점을 보여줘야 해요.
4.1 비효율적인 방법
처음엔 단순하게 생각해서, 애플리케이션에서 계산하도록 했어요:
const getAlcoholDetail = async (alcoholId) => {
// 1. 전통주 조회
const alcohol = await Alcohol.findOne({ index: alcoholId });
// 2. 리뷰 전부 조회
const reviews = await Review.find({ alcohol: alcohol._id });
// 3. 애플리케이션에서 계산
const reviewCount = reviews.length;
const averageRating = reviews.reduce((sum, r) => sum + r.rating, 0) / reviewCount;
return {
...alcohol,
reviewCount,
averageRating
};
};
문제점:
- DB 쿼리 2번 (전통주 조회 + 리뷰 조회)
- 리뷰가 1000개면 1000개 전부 메모리에 올림
- 애플리케이션에서 계산하느라 느림
리뷰가 10개일 때는 괜찮은데, 100개, 1000개 되면 느려져요.
4.2 Aggregation Pipeline으로 해결
MongoDB Aggregation을 쓰면 한 번의 쿼리로 끝납니다!

4.3 Aggregation Pipeline 이해하기
Aggregation Pipeline은 여러 단계(stage)를 거쳐서 데이터를 처리해요. 파이프처럼 데이터가 흘러가면서 변환되는 거죠.
Stage 1: $match (필터링)
{ $match: { index: parseInt(alcoholId) } }
SQL로 치면 WHERE index = 123 같은 거예요. 조건에 맞는 전통주 하나를 찾습니다.
// 입력: 전체 Alcohol 컬렉션
// 출력: index가 123인 문서 1개
{
_id: ObjectId("alcohol456"),
index: 123,
alcoholName: "막걸리",
// ...
}
Stage 2: $lookup (JOIN)
{
$lookup: {
from: 'reviews', // 어떤 컬렉션과 조인?
localField: '_id', // Alcohol의 어떤 필드?
foreignField: 'alcohol', // Review의 어떤 필드와 매칭?
as: 'reviews' // 결과를 어떤 필드에 담을지?
}
}
이게 SQL로 치면:
SELECT *
FROM alcohols a
LEFT JOIN reviews r ON a._id = r.alcohol
WHERE a.index = 123
근데 MongoDB는 배열로 담아요:
// 입력
{
_id: ObjectId("alcohol456"),
alcoholName: "막걸리"
}
// 출력
{
_id: ObjectId("alcohol456"),
alcoholName: "막걸리",
reviews: [
{ _id: "review1", rating: 5, content: "맛있어요" },
{ _id: "review2", rating: 4, content: "괜찮아요" },
{ _id: "review3", rating: 5, content: "최고!" }
]
}
Stage 3: $addFields (필드 추가)
{
$addFields: {
reviewCount: { $size: '$reviews' },
averageRating: {
$cond: {
if: { $gt: [{ $size: '$reviews' }, 0] },
then: { $avg: '$reviews.rating' },
else: 0
}
}
}
}
여기서 새로운 필드를 추가해요:
reviewCount: 리뷰 개수
{ $size: '$reviews' } // 배열 길이 = 3
averageRating: 평균 별점
{
$cond: {
if: { $gt: [{ $size: '$reviews' }, 0] }, // 리뷰가 1개 이상이면
then: { $avg: '$reviews.rating' }, // 평균 계산
else: 0 // 리뷰 없으면 0
}
}
`$avg: '$reviews.rating'`는 배열의 rating 필드들을 평균내는 거예요:
reviews: [
{ rating: 5 },
{ rating: 4 },
{ rating: 5 }
]
// $avg → (5 + 4 + 5) / 3 = 4.67
리뷰가 없으면 0으로 나누기 에러가 나니까 $cond로 체크했어요.
최종 출력:
{
_id: ObjectId("alcohol456"),
index: 123,
alcoholName: "막걸리",
reviews: [...], // 전체 리뷰 배열
reviewCount: 3, // 새로 추가된 필드
averageRating: 4.67 // 새로 추가된 필드
}
마무리 & 배운 점
1. 스키마 설계를 처음부터 신경 써라
나중에 바꾸려면 데이터 마이그레이션해야 해서 정말 힘들어요.
- 인덱스 설계
- 참조 관계
- ID 시스템
2. ObjectId vs 일반 값 구분 명확히
참조 필드에는 반드시 ObjectId를 넣어야 populate()가 작동해요.
3. 에러 메시지를 친절하게
"에러 발생"보다 "이미 리뷰를 작성하셨습니다"가 훨씬 좋죠.
4. Controller와 Service 분리
처음엔 귀찮아도 나중에 정말 편해요. (특히 테스트할 때)
5. 외부 서비스 정리 잊지 말기
DB만 지우고 S3 이미지를 안 지우면 용량만 차지하고 돈만 나가요.
이번에 구현한 리뷰 시스템을 기반으로 아래 기능들을 추가해나갈 수 있을 것 같습니다:
- 리뷰 좋아요 기능
- 리뷰 신고 기능
- 리뷰 정렬 (최신순, 별점순, 좋아요순)
- 리뷰 필터링 (별점별)
- 리뷰 페이지네이션
- 리뷰 이미지 여러 장 업로드
긴 글 읽어주셔서 감사합니다!
궁금한 점이나 피드백 있으면 댓글로 남겨주세요 🍶
전체 코드는 https://github.com/Hanrann6/Jujeonboori에서 확인할 수 있습니다.
'𝐄𝐰𝐡𝐚 > 캡스톤' 카테고리의 다른 글
| [Node.js] AI 전통주 큐레이션 서비스 Back-end 개요 (0) | 2025.05.30 |
|---|